안녕하세요. ^^
주식회사 아인시스 아이엔씨 입니다.
오늘은 Rocky Linux Bonding 설정하는 방법에 대해 알아보겠습니다~
밑에 따라서 진행하면 금방입니다!
1. 서버 OS Version 확인 및 nmcli 확인

Rocky Linux 9.7 버전에서 진행합니다.
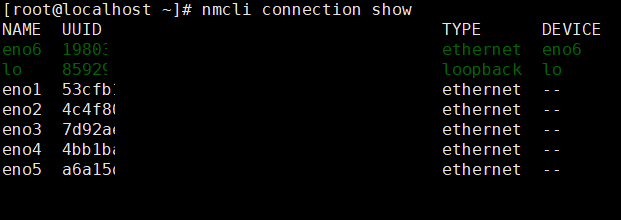
nmcli도 확인해 줍시다~
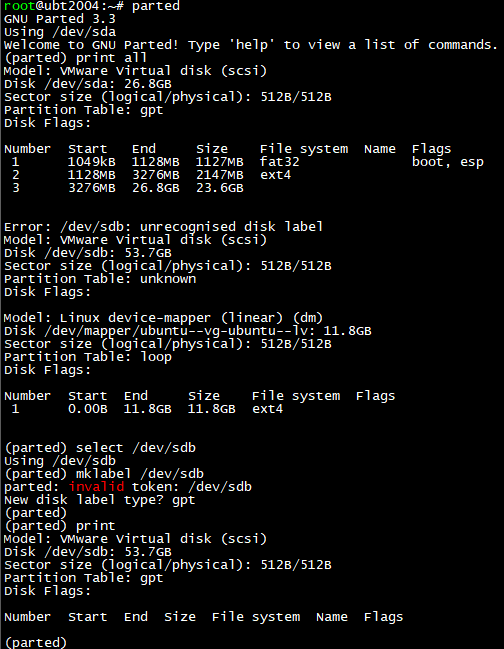
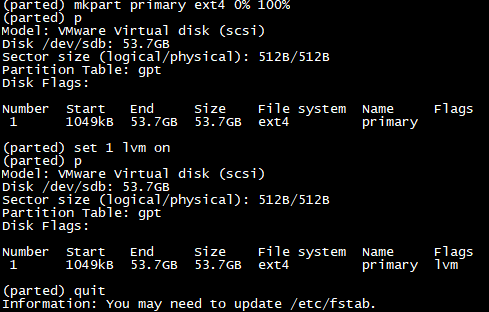
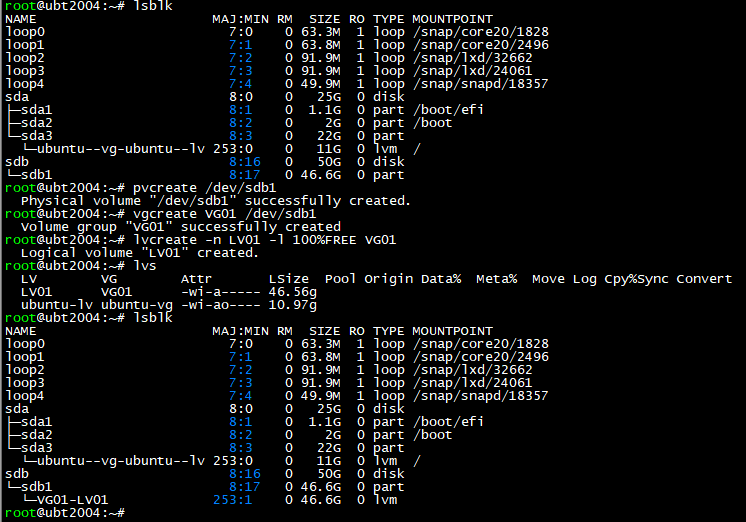
2.사용 할 포트 찾기


포트 찾기를 ethtool -p를 입력해서 확인 할 수 있습니다.
2포트로 묶는 방식이라 하나 더 찾아서 확인해 주세요.
저는 eno1 / eno2 쓸 예정입니다.
3. nmtui에서 bonding port 설정하기

입력하면 창 하나가 활성화 됩니다.
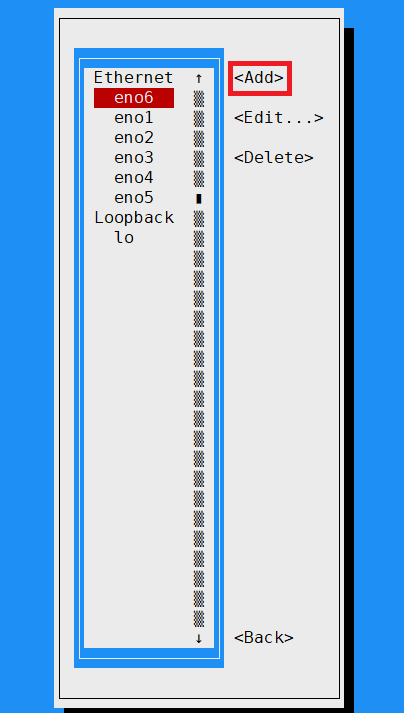

Add 확인 후 Bond에 Create를 눌러 줍니다~
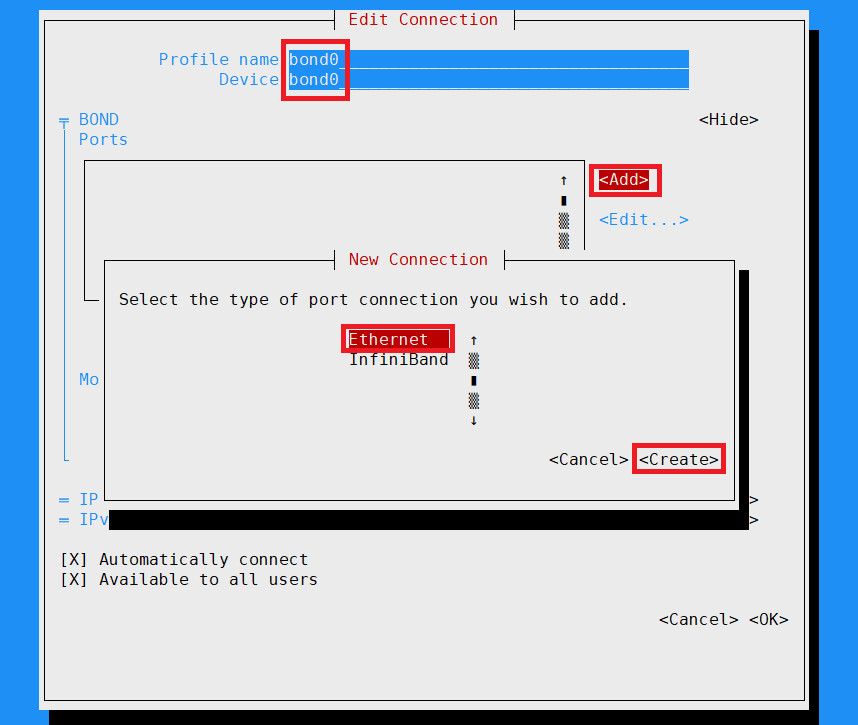
bond0로 이름 설정을 똑같이 해주세요.
그리고 Add 누르고 Ethernet Create로 넘어가 줍시다.

bond0-slave1로 바꿔 주세요.
Device는 아까 포트 찾은 이름으로 해주세요.
나머지 하나는 사진 첨부 따로 안하겠습니다.
똑같이 Add 누르고 Ethernet Create 눌러주시고
Profile name : bond0-slave2
Device : eno2 로 설정해 주시고 OK 눌러주세요.
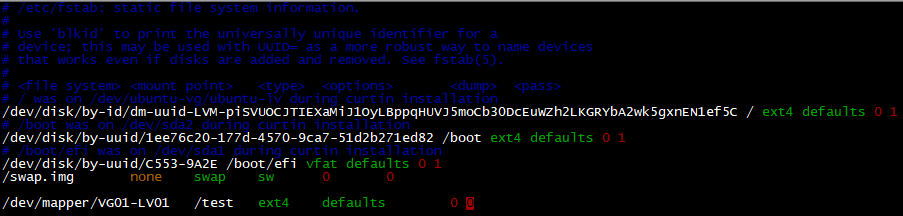
4. bonding mode 설정 후 확인 하기
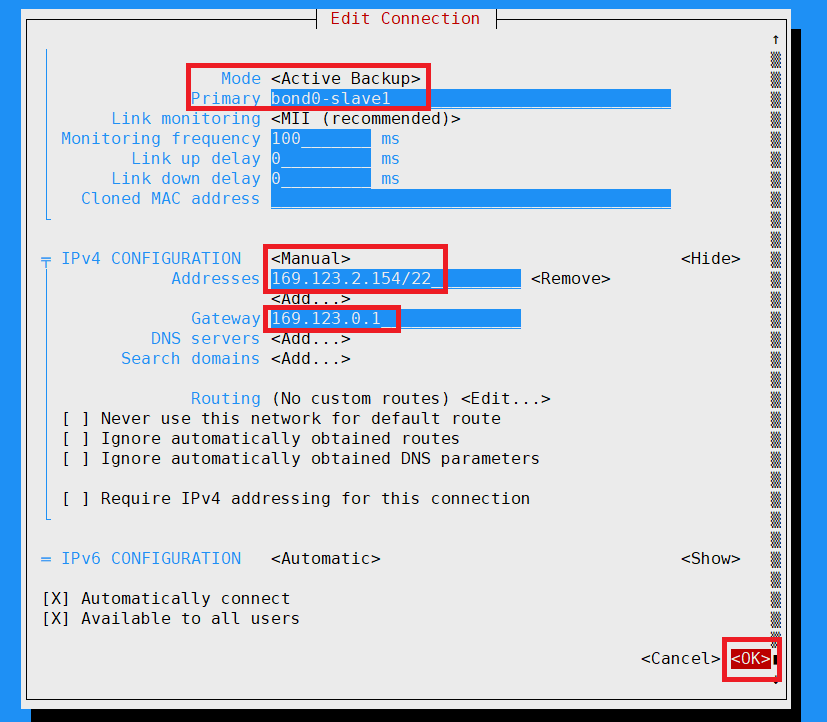
사진에 나와 있는 Mode 및 Primary 설정
IPv4 Manual로 바꿔 주시고 IP 세팅해 주세요.
이렇게 하고 OK하면 설정 완료 입니다!

설정하고 bonding 이름 및 포트타입 이름 다 확인해 줍니다.


사진 나온 것처럼 확인하면 완료입니다!
작업을 마치며..
이상으로 Rocky Linux Bonding 설정 방법에 대해 알아보았습니다.
다음 시간에도 유익한 내용으로 찾아뵙겠습니다.
긴 글 읽어 주셔서 감사합니다.
'기술자료 > 서버' 카테고리의 다른 글
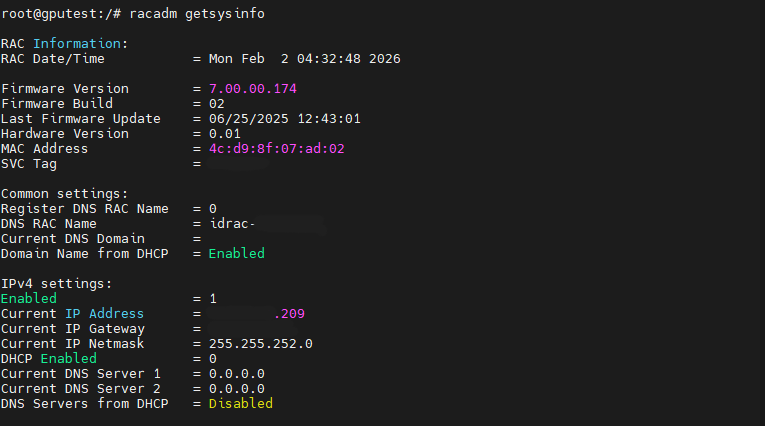
| [서버] DELL idrac Tool을 이용한 idrac ip변경 방법 (Linux용) (0) | 2026.02.02 |
|---|---|
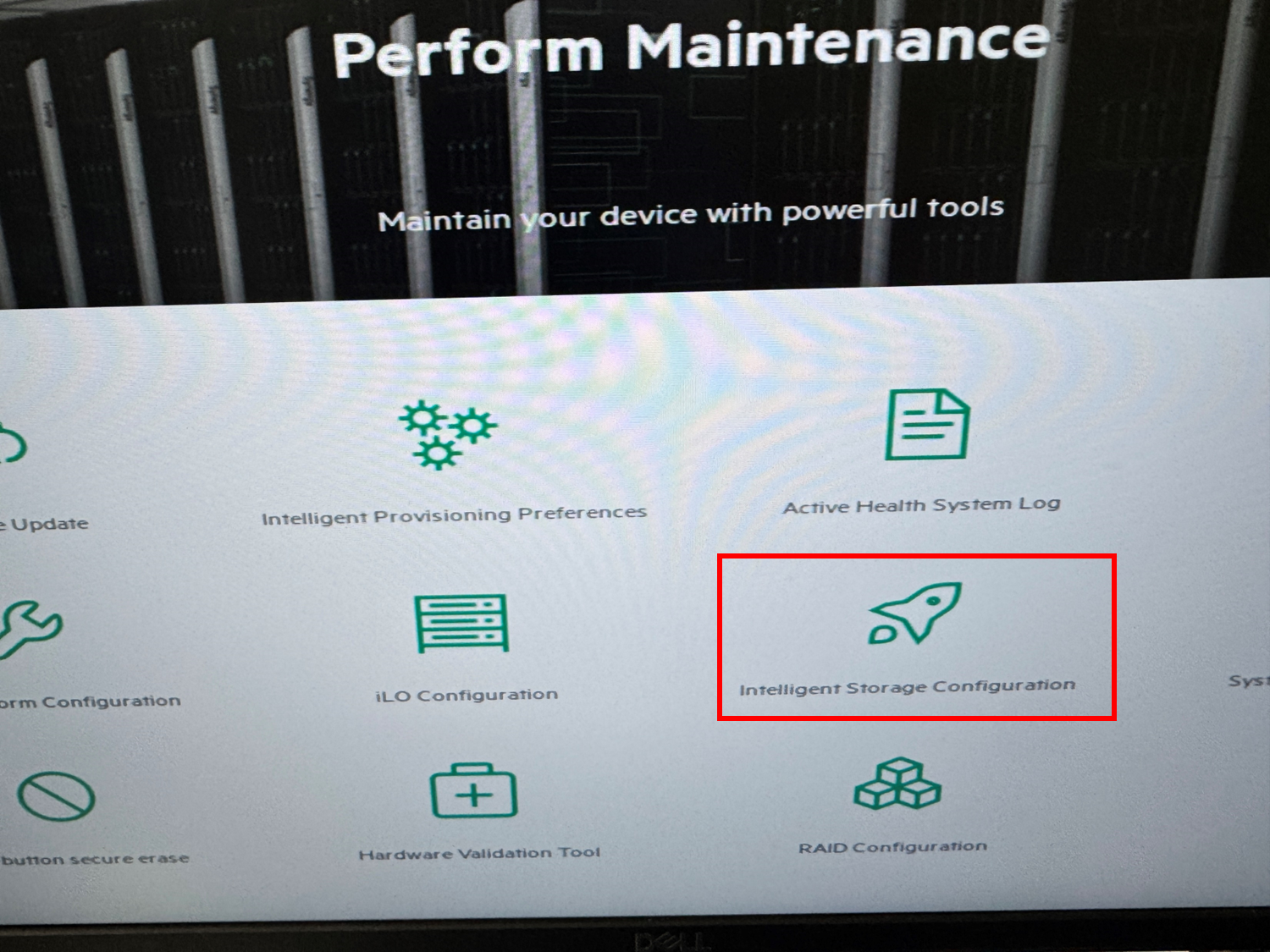
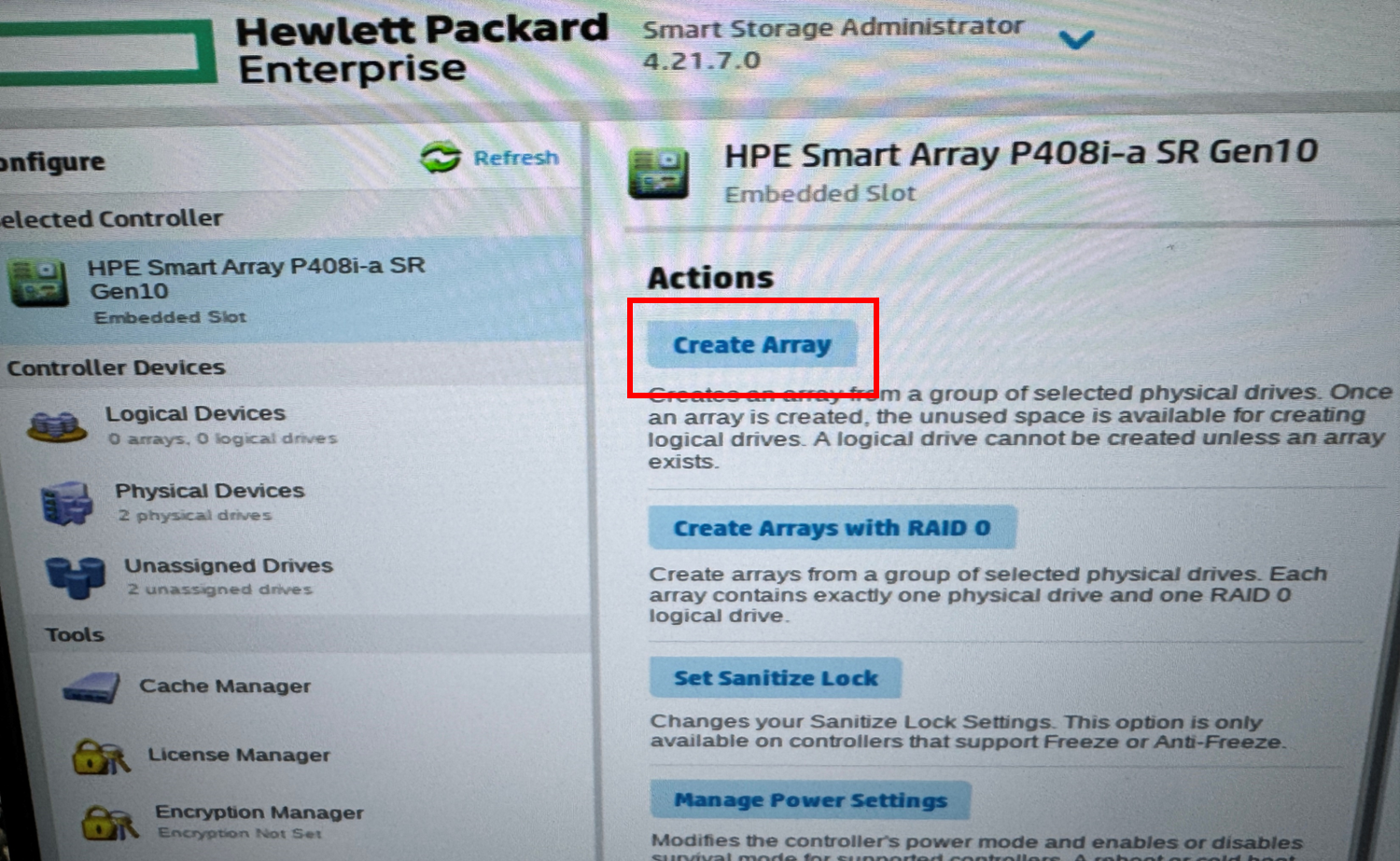
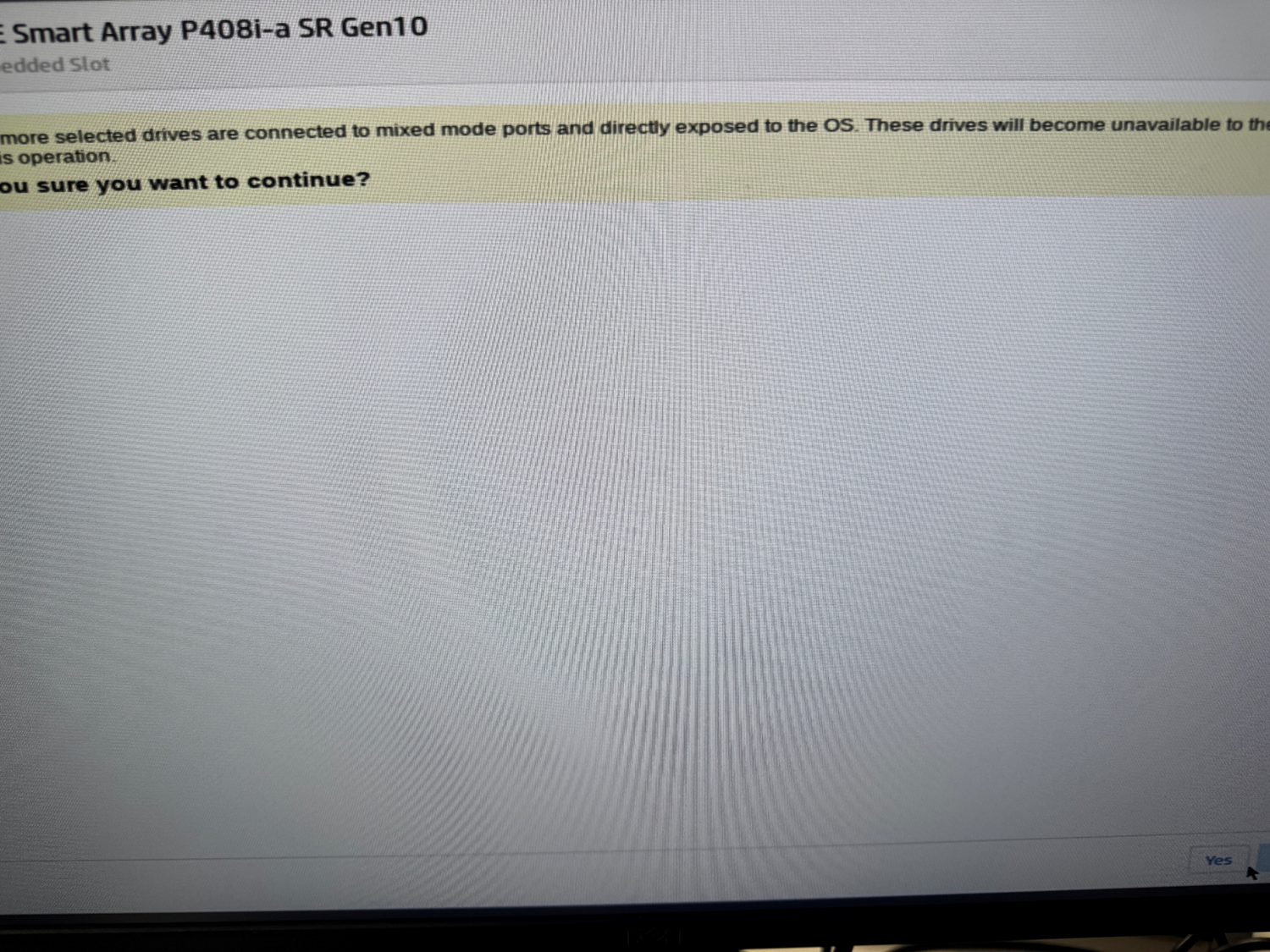
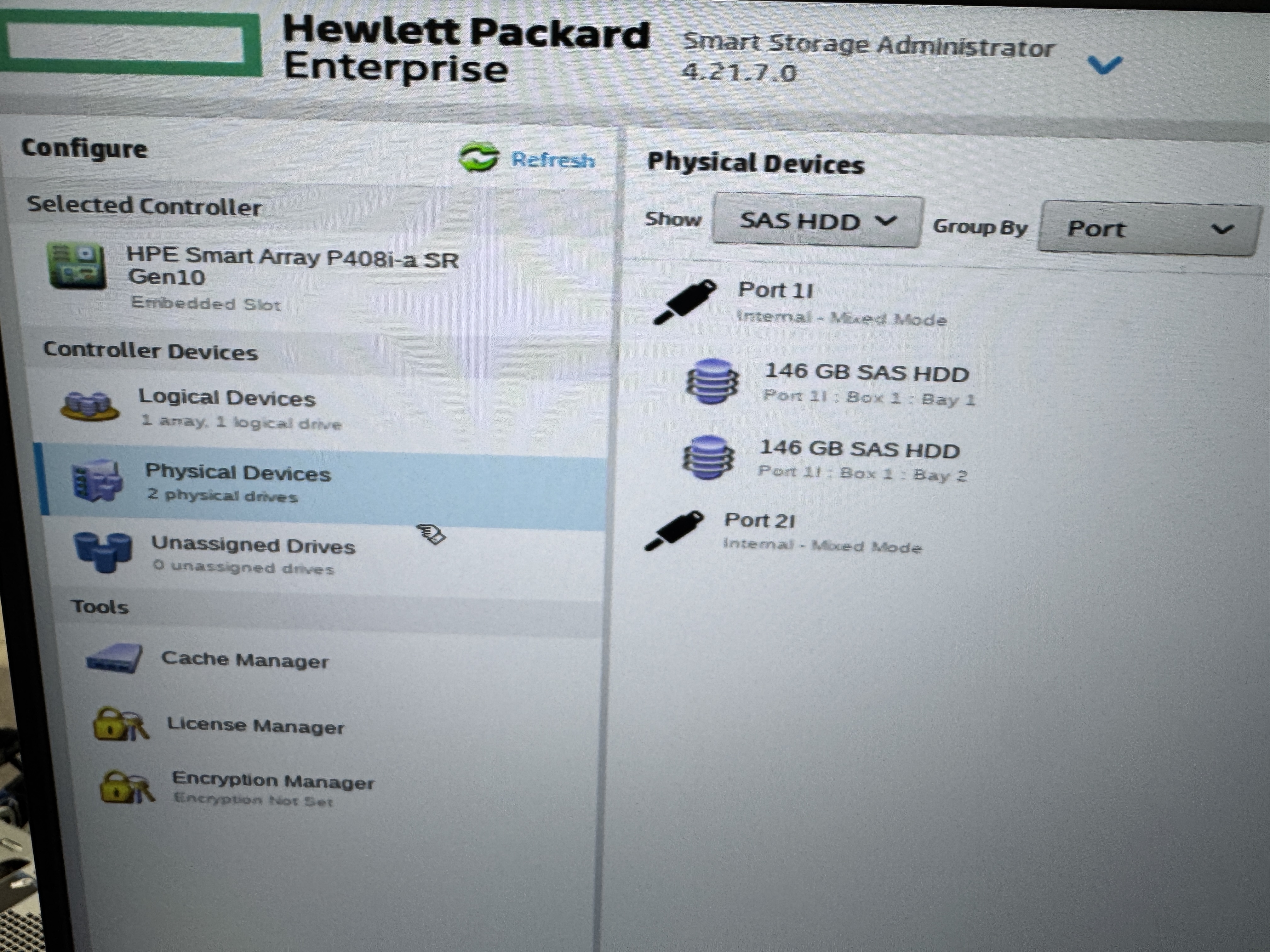
| [서버] HPE DL360 Gen10 서버 SSA(Smart Storage Administrator)을 통한 레이드(RAID) 구성 방법 (0) | 2026.02.02 |
| [서버] DELL R7525 UEFI0391 경고: NUMA(NPS) 최적화 가이드 (0) | 2026.01.29 |
| [서버] DELL SERVER 펌웨어 업데이트 방법 (0) | 2025.11.24 |
| [서버] DELL OMSA(OpenManage Server Administrator)를 사용해서 서버 관리하기(Windows server) (0) | 2025.11.11 |